

换了个课上摸的更符合自己最近性格的阴沉头像 虽然看起来很阴沉但换完还是很开心(。

我好像越來越不相信語言的力量,比如說,我曾經認為人和人之間是能夠通過交流而相互理解的。
現在我更傾向與認為,人和人之間能夠達成相互理解,一個是基於類似的經歷體驗,另一個是基於個人的選擇傾向,另外可能還有些模糊曖昧的因素影響著我們,但這些和「語言」完全沒有關係。
甚至於我憎恨語言的力量,當有人使用它隱瞞、欺騙、在其他人心中留下無形傷害的時候。

好喜欢现在陶艺教室的open studio。绝大多数是女性,还有很少几个草食男。除了不同level和不同class的人会在一起练习于是可以被别人inspire(我超爱去逛放等待烧和烧好后的shelves)之外,是一个让我感觉很safe的练习夸人和接受被夸的space。
对于出生就浸泡在等级社会里的东亚人,称赞几乎是条件反射地勾起对权力地位的感知和确认:觉得自己不配得到“更好的人”的赞美、赞美别人总是下意识去“矮着身子”过度浮夸然后自我厌恶、表扬来自上位者就会格外雀跃……反而是不trigger任何无关dynamic、平等坦诚地表达admire和接受别人的admire是需要有意识地unlearn和learn的过程。而且想清楚称赞和被称赞跟"Who I am"没有关系是一回事,练习到能磨平几十年的条件反射、back to the natural way是另一回事。
想要达到那种像称赞今天天气很好一样称赞别人、像感觉到今天有一个很好天气一样被别人称赞的状态。

#LoRA :Low-Rank Adaptation of Large Language Models
昨天速学LoRA今天就要给友友们讲了!紧张!希望没讲错!顺便把拖了很久的 #DreamBooth 一并讲了。
要讲LoRA就要先讲模型finetune。模型的finetune指的是什么呢?其实就是当你有一个现成的,很厉害的大模型(pre-trained model),你想要让它学一些新知识,或者完成一些更面向具体应用的子任务,或者只是为了适配你的数据分布时,就需要拿你的小数据去对模型进行重新训练。这个训练不能训太久,否则模型就会过拟合到你的小样本数据上。
pre-train + finetune 是机器学习非常常见的组合,在应用上有很大价值。但是最常见的一个问题就是“遗忘”。模型会在finetune过程中不断忘记之前已经记住的内容。
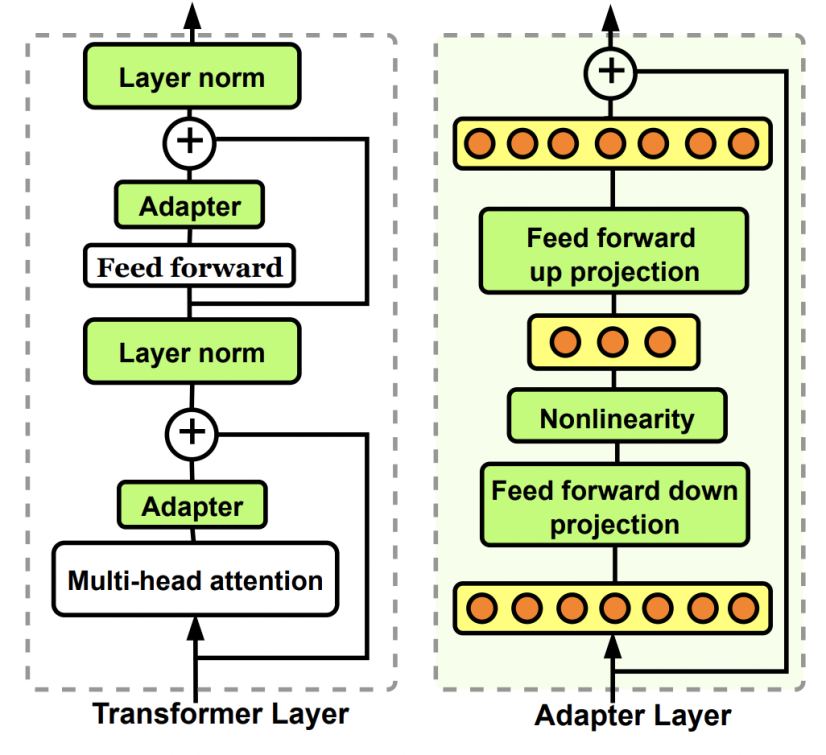
常见的解决方案中,一个是replay,就是也把原始知识过一遍;第二个是正则化,通过正则项控制模型参数和原始参数尽量一致,不要变太多;还有一个是Parameter isolation(参数孤立化),这个是通过独立出一个模块来做finetune,原有的模型不再更新权重。
参数孤立化是最有效的一种方式,具体有好几种实现方式,例如Adaptor(P1)就是在原模型中增加一个子模块,固定原模型,只训练子模块。是不是听起来很熟悉?是的,ControlNet就是一种类似Adaptor的方法,同理还有T2I-Adapter,也是通过增加子模块来引入新的条件输入控制。
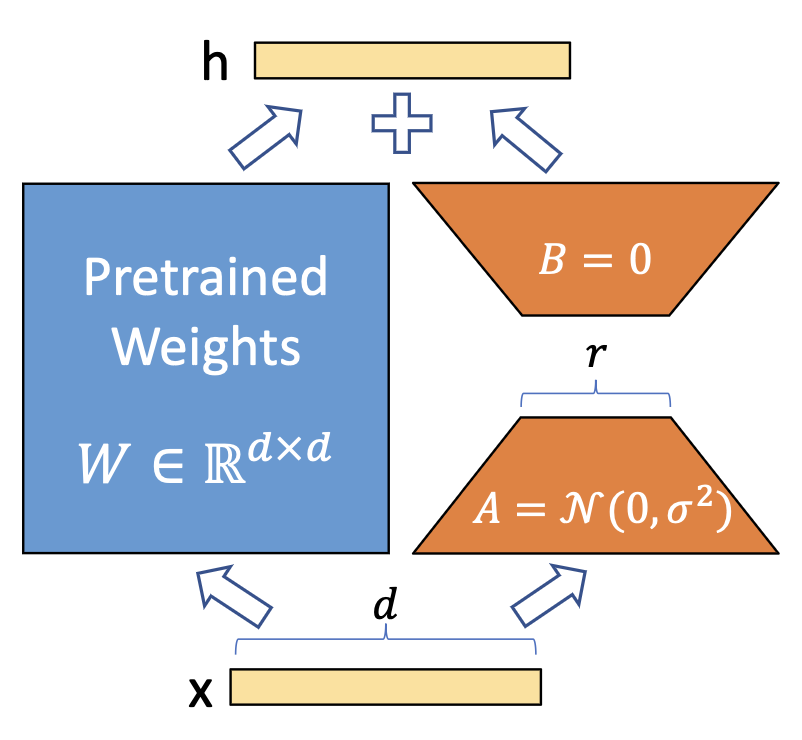
LoRA则是另一种参数孤立化策略。如P2,它利用低秩矩阵来替代原来全量参数进行训练,从而提升finetune的效率。
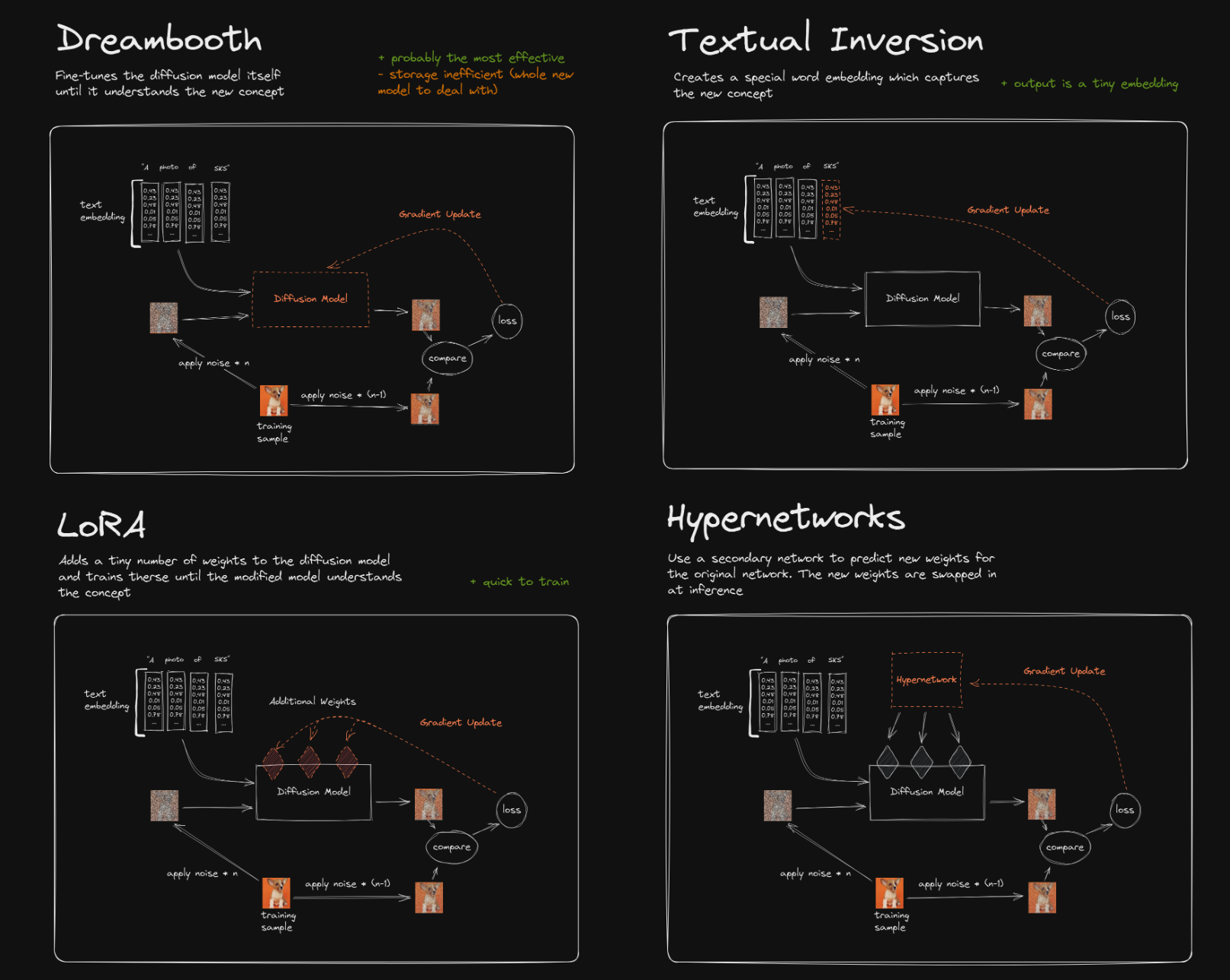
我们可以拿来和DreamBooth对比一下。P3是个很清晰的对比图。
对于DreamBooth来说,它是直接更新整个大模型的权重来让模型学习新概念的。虽然可以通过正则项避免遗忘,但是finetune后的模型依然非常大(和原模型一样大)。
而使用LoRA后,LoRA影响的只是其中一小部分(通过低秩矩阵叠加到大模型网络上)。所以finetune起来更快,更不吃资源,而且得到的finetune模型非常小,使用起来方便很多。
由于LoRA在结构上是独立于大模型的,所以它甚至有一个额外的好处是替换大模型可以得到不同的令人惊喜的结果。而且也非常方便进行模型融合。
在使用上来说,LoRA很像是模型的“插件”,你可以在基础模型上叠加你想要的效果,或者把各种你想要的效果加权组合叠在一起,可以产生很多令人惊喜的结果。
当然LoRA由于是finetune模型,所以画风会趋于单一,是好是坏见仁见智,在需要固定画风orID的时候能发挥令人惊喜的用处。
看到附近年底有six明年有大悲的巡演……又开始希望能顺利活到那个时候 ![]() 虽然看起来只是不着调的理由 但当作一种心愿之后就有那么一点想要去实现了
虽然看起来只是不着调的理由 但当作一种心愿之后就有那么一点想要去实现了 ![]()
最近明明睡得挺多的怎么黑眼圈还是那么重 ![]()

多伦多dt 理发
在Christie和Bathurst之间那家韩国人开的H2Goa找了一位叫Mi Young 的姐姐,姐姐好牛逼啊!我是从齐脖子中段剪到齐耳,从平齐剪到有些包包头的效果,刚开始说了一句半、姐姐直接打断我:show me the photo ![]() 然后姐姐手速像聊天风格一样雷厉风行,十分钟大轮廓剪完了……!加上她开小差去给另一个顾客烫头,以及后来给我吹头和修细节,一共也就用了半个钟头……下手超级果断,一句废话都不说。效果么是我在多伦多三年来剪的最满意的一个头……加上小费和税60出头
然后姐姐手速像聊天风格一样雷厉风行,十分钟大轮廓剪完了……!加上她开小差去给另一个顾客烫头,以及后来给我吹头和修细节,一共也就用了半个钟头……下手超级果断,一句废话都不说。效果么是我在多伦多三年来剪的最满意的一个头……加上小费和税60出头 ![]()
早上的噩梦
早上的噩梦梦见和一栋房子里的朋友约着出去玩,但是大家一瞬间都收拾好了我还是很累不想动,越是准备越发现要做的事情越多。我住在车库里,进出的门是很大的电动的卷帘门,但是好像坏了,变得不是很可控,梦里要出门的时候无论如何也锁不上,可以从外面被随意打开,我的私人物品和空间因此会被随意摆弄和进出。门外正巧有三个小孩在玩,一直不怀好意的样子盯着我修门,他们应该知道了我离开后这扇门很可能不会正常锁上,准备趁我离开进去玩。朋友给我的压力很大,责怪我为什么不快点,我不得不准备离开,于是只是把门从内部用塑料绳子绑上,再从另一个出口离开,期待这样能对我的空间稍作保护。我在门口观察了一会那三个小孩,果然他们在我离开之后马上就朝着那个门进攻,塑料绳子并未带来多少保护,他们在我所居住的车库进进出出,我本想录下他们破坏我的屋子的视频,去寻找他们的监护人弥补自己的损失,但是那时的我突然一点力气也没有,只能这样看着自己的空间被人破坏。这时那三位小孩的家教路过,我上前寻求帮助,也询问三位小孩的住处和家长,他答应帮我传递消息。梦就这样结束了,梦里和朋友的出行也没有后续。醒来之后想起梦里的故事几次,还是能感觉到梦里情绪在蔓延。在住所也无法得到的安全感,被陌生小孩霸凌,和朋友行事节奏的分歧,这些具体的事件当然是睡梦中的我的大脑所虚构的,但情绪上也许继承了清醒时的我内心所深埋的不安,当作故事写下来也许会轻松一点吧 ![]()
先简单写一写引文,最初我第一次写ai绘画的时候,放过图一展示ai绘画中img2img的效果。当时的原理是把左图加一些高斯噪声(撒撒黑胡椒)然后作为底图来基于它生成。所以基本上色块分布是接近的,但是很难控制更细节的了。
今年爆炸性的controlnet,则是可以通过任何的条件控制网络生成。其实就是换一种方式让模型听话。原来模型只能得到一个文本的生成引导,现在它可以听懂任何基于图片提取的信号了,只要你拿一组成对的图片去训练!
这个方式出来以后极大地扩展了可玩性,而且官方已经提供了非常多常用的训练好的控制网络。比如说图二由深度图控制,图三由人体姿态控制。只要你想,你可以自己训练,比如说就有人训练了手部骨骼控制器,解决了ai不会画手的问题。
这些控制结果还可以一起用,比如图4,我从图a拿人的姿态,图b拿景色的深度,合在一起就可以生成我想要的一个人站在这个街景中的图片。
原理上其实实现得比较简单,就是把整个网络复制了一份,固定原始网络和它的输入,但是另一个control网络的输入就是控制条件(深度、姿态等)然后把两个输入和输出加起来,用成对的数据集(输入是深度图输出是原图这种感觉)去训练控制网络,达到控制条件能够很好控制生成结果的程度,就训练好啦!
#论文导读 @mature

@gozmo
看日常演技:
老番-電腦線圈(看磯光雄)/給桃子的信、狼的孩子雨和雪(看井上俊之)/吉卜力系都很強
比較新的-向山進發(看野中正幸、松本憲生)/搖曳百合/不當哥哥了
看動作戲:
比較老的-攻殼(寫實)/星際牛仔:天國之扉(寫實)/異邦人:無皇刃譚(寫實巔峰)/摔跤的羅密歐與茱麗葉(大平晉也的流麗與崩壞)/光之美少女裡有很多馬越嘉彥他們東映系的動作戲
比較新的-鬼滅、我的英雄學院(雖然有點土但如果想研究作畫是不可能繞過這兩個的⋯中村豐、阿部望、前並武志等人貢獻了大量神作畫)/kill la kill、天元突破紅蓮螺旋(看すしお、吉成曜等當代金田系)/進擊的巨人(看今井有文華麗空間馬戲)/旋轉少女(看渡邊啟一郎)/一拳超人、路人100(不分類了動作戲全都很強)
看導演個人風格
比較老的-川尻善昭/押井守所有的(夾帶私貨了,主要是我個人喜歡😂⋯不過大家都看過了吧)
新的-近年比較喜歡的導演是松本理惠(京騷戲畫/血界戰線)和齋藤圭一郎,後者因為孤獨搖滾爆火了,但我是從漂流教室第八話開始關注他的,是非常年輕有才能、有獨特詩意視角的新銳導演。
平淡細膩風格的導演比較推山田尚子。
.
就好像那些当下无法被察觉的感知和无法自然产生的回应,在事后报复性地回到我的身体和脑海里……被延迟的感受趁着暗自隔绝的时候快速生长,从内部淹没我的感官变成窒息的痛苦。轴线上错开的感知告诉我,我不曾与他人真正相遇、不曾共享过世界与瞬间,永远是错过和隔绝带来的过错,永远是一位等待裁决的异端 ![]()
害怕白天和太阳 害怕明亮的街道 不想看见阳光下的人群 但是白天的时间越来越长了……越想越觉得有点痛苦 ![]()
![]()
每天都刷新看看我的包裹进展 每天都看见它安静地呆在同一个机场 ![]() (其实也没有几天但是越刷越急
(其实也没有几天但是越刷越急

室友韧带断裂了,必须坐轮椅出行,我才发现我们宿舍楼进门是没有斜坡的,而且宿舍里上床下桌的设计,垂直的梯子,脚有问题根本爬不上去睡不了觉。她只好申请住临时宿舍,好不容易找到个有下铺的房间。
那么多级台阶,她对象把她背上来,我再帮她推轮椅。这是我第一次推轮椅,才发现地面上那么多道门槛和沟壑,过道那么窄根本无法转弯,我推着一百多斤左摇右晃,几百米累了一身汗。在一个专为所谓的健全人设计的世界里,稍微变成弱者,就会生活得好辛苦啊。
做梦梦见在上课 讲课的是一个以前的老师 印象里是那种讲课讲的蛮有趣 但是平时讲话让人不太爱听的类型 梦里快要放学的时候那个老师突然开始批评我 都是一些无缘无故的理由 说收拾东西为什么这么慢之类的 梦里我很生气 但是只是抬头看着他一眼 然后深吸了一口气继续收拾我的东西 这个老师又开始继续挑衅说你就是因为这样没有脾气 连生气都不敢 我对你讲话这么不公平都没反应 这样下去是不行的 那个时候梦里也觉得他说的很有道理 其实自己也很想试试发脾气生气的感觉 但最后还是什么都没有做到 想着既然一开始没有发作 为什么后来要因为他的言语改变呢 凭借一种叛逆的心情去忍耐 不管是梦里还是醒过来之后 心情都很复杂 ![]()

昨天激情码字写了一篇海外观鸟ABC。春天到了,正是观鸟好时节。


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
我为平静的生活做了很多。
加入于 2022年05月
